




LLM Development Services
Build powerful language AI with our expert LLM engineers. We develop custom large language models, fine-tune foundation models, and integrate LLMs into your business systems. From chatbots to content generation, our team delivers production-ready AI that understands your domain.
Trusted by 3,500+ Brands Worldwide








Are You Struggling to Make Large Language Models Work for Your Business?
Generic LLMs hallucinate, go off-brand, and lack your domain knowledge. If these challenges sound familiar, you need a trusted expert LLM partner.
ChatGPT gives generic answers about your industry
Public LLMs lack your domain data. Our expert team fine-tunes models for accurate, domain-specific responses.
LLM outputs hallucinate facts and mislead users
Uncontrolled language models hallucinate. Our llm development company implements RAG, guardrails, and validation for factual outputs.
Integration with your systems is harder than expected
Connecting LLMs to your CRM and databases requires expertise. Our llm integration services handle the complex engineering.
API costs keep growing as usage scales
Pay-per-token pricing adds up fast. Our custom llm development services deploy open-source models for predictable infrastructure costs.
Your team cannot keep up with the pace of LLM releases
New models launch monthly. Our large language model development services keep you current without rebuilding everything.
Data privacy concerns block LLM adoption
External API data sharing is risky. Our llm development solutions deploy private models on your own infrastructure.
Trusted LLM Development at Scale
With 15+ years of experience, we have delivered 700+ projects across 20+ industries. Our 120+ in-house experts build large language models that work in production.
0+
Projects delivered successfully using 50+ technologies
0+
Projects delivered successfully using 50+ technologies
In-house experts with average 4+ years of experience
0+
0+
In-house experts with average 4+ years of experience
0Mn+
App store downloads with 96%+ crash-free users
0Mn+
App store downloads with 96%+ crash-free users
0%
Senior-level AI specialists on staff
0%
Senior-level AI specialists on staff
Happy clients and 60% recurring business
0%
0%
Happy clients and 60% recurring business
0+
Industries served across 25+ countries
0+
Industries served across 25+ countries
Our Core LLM Development Services
Custom LLM Development
We build large language models trained on your domain data for industry-specific understanding and generation accuracy.
Domain-Specific Training:
We train LLMs on your proprietary data including documents, conversations, and knowledge bases for expert-level understanding.
Open-Source Model Customization:
We customise Llama, Mistral, and other open-source models for private deployment on your own infrastructure securely.
Enterprise-Grade Architecture:
We design LLM systems with load balancing, caching, and failover for reliable production performance at scale.
Multi-Model Orchestration:
We build systems that route queries to the optimal model based on complexity, cost, and accuracy requirements.
LLM Fine-Tuning
We adapt foundation models to your use case through fine-tuning techniques that improve accuracy and reduce hallucinations dramatically.
Instruction Fine-Tuning:
We train models to follow your specific instructions and output formats consistently for reliable business workflows.
RLHF & Preference Training:
We use human feedback to align model outputs with your quality standards and brand voice for better results.
LoRA & QLoRA Techniques:
We use efficient fine-tuning methods that deliver custom model quality at a fraction of the full training cost.
Evaluation & Benchmarking:
We measure fine-tuned model performance against baselines to prove improvements before production deployment.
RAG (Retrieval-Augmented Generation)
We build RAG systems that ground LLM responses in your real data, eliminating hallucinations and ensuring factual outputs.
Knowledge Base Integration:
We connect your LLM to internal documents, databases, and APIs so it answers from your real data, not guesses.
Vector Database Setup:
We build and optimize vector stores using Pinecone, Weaviate, or ChromaDB for fast, accurate retrieval.
Chunking & Indexing Strategy:
We design the data pipeline that breaks documents into searchable chunks optimized for your specific queries.
Citation & Source Tracking:
We build systems that show which documents the LLM used to generate each answer for transparency and trust.
LLM System Integration
We connect large language models to your existing business systems, enabling AI-powered workflows across your organization.
API Architecture Design:
We design the integration layer with authentication, rate limiting, and fallback mechanisms for reliable, production-grade AI deployment.
CRM & ERP Connection:
We connect LLMs to Salesforce, HubSpot, SAP, and other platforms so AI works within your existing workflows.
Chat & Messaging Integration:
We deploy LLM-powered bots on web, mobile, WhatsApp, and Slack from a unified codebase for consistent experiences.
Legacy System Bridging:
We connect modern LLMs to older systems through APIs and middleware without requiring costly platform rewrites.
AI Consulting & Strategy
We help you choose the right LLM approach, model, and architecture for your large language model development services project.
LLM Readiness Assessment:
We evaluate your data, infrastructure, and use cases to determine the fastest path to LLM value for your business.
Model Selection Guidance:
We recommend GPT-4, Llama, Mistral, or Claude based on your accuracy, cost, and privacy requirements.
Build vs Buy Analysis:
We help you decide whether to fine-tune, use APIs, or train from scratch based on your specific budget and needs.
Implementation Roadmap:
We create a phased plan with timelines and milestones so you can hire llm developers and move forward with confidence.
LLM Monitoring & Optimization
We track performance, reduce costs, and continuously improve your LLM systems after deployment with ongoing llm services.
Output Quality Monitoring:
We track response accuracy, relevance, and safety metrics daily to catch degradation before it impacts users.
Cost Optimization:
We reduce API and compute costs through caching, prompt optimization, and model selection strategies.
Prompt Engineering:
We design and optimize prompt templates that consistently produce high-quality outputs for your specific workflows.
A/B Testing Framework:
We test different models, prompts, and configurations to continuously improve performance and user satisfaction.
Our Core LLM Development Services
We provide comprehensive llm services from custom model training to RAG implementation to enterprise integration for any business.
We build large language models trained on your domain data for industry-specific understanding and generation accuracy.
Domain-Specific Training:
We train LLMs on your proprietary data including documents, conversations, and knowledge bases for expert-level understanding.
Open-Source Model Customization:
We customise Llama, Mistral, and other open-source models for private deployment on your own infrastructure securely.
Enterprise-Grade Architecture:
We design LLM systems with load balancing, caching, and failover for reliable production performance at scale.
Multi-Model Orchestration:
We build systems that route queries to the optimal model based on complexity, cost, and accuracy requirements.
We adapt foundation models to your use case through fine-tuning techniques that improve accuracy and reduce hallucinations dramatically.
Instruction Fine-Tuning:
We train models to follow your specific instructions and output formats consistently for reliable business workflows.
RLHF & Preference Training:
We use human feedback to align model outputs with your quality standards and brand voice for better results.
LoRA & QLoRA Techniques:
We use efficient fine-tuning methods that deliver custom model quality at a fraction of the full training cost.
Evaluation & Benchmarking:
We measure fine-tuned model performance against baselines to prove improvements before production deployment.
We build RAG systems that ground LLM responses in your real data, eliminating hallucinations and ensuring factual outputs.
Knowledge Base Integration:
We connect your LLM to internal documents, databases, and APIs so it answers from your real data, not guesses.
Vector Database Setup:
We build and optimize vector stores using Pinecone, Weaviate, or ChromaDB for fast, accurate retrieval.
Chunking & Indexing Strategy:
We design the data pipeline that breaks documents into searchable chunks optimized for your specific queries.
Citation & Source Tracking:
We build systems that show which documents the LLM used to generate each answer for transparency and trust.
We connect large language models to your existing business systems, enabling AI-powered workflows across your organization.
API Architecture Design:
We design the integration layer with authentication, rate limiting, and fallback mechanisms for reliable, production-grade AI deployment.
CRM & ERP Connection:
We connect LLMs to Salesforce, HubSpot, SAP, and other platforms so AI works within your existing workflows.
Chat & Messaging Integration:
We deploy LLM-powered bots on web, mobile, WhatsApp, and Slack from a unified codebase for consistent experiences.
Legacy System Bridging:
We connect modern LLMs to older systems through APIs and middleware without requiring costly platform rewrites.
We help you choose the right LLM approach, model, and architecture for your large language model development services project.
LLM Readiness Assessment:
We evaluate your data, infrastructure, and use cases to determine the fastest path to LLM value for your business.
Model Selection Guidance:
We recommend GPT-4, Llama, Mistral, or Claude based on your accuracy, cost, and privacy requirements.
Build vs Buy Analysis:
We help you decide whether to fine-tune, use APIs, or train from scratch based on your specific budget and needs.
Implementation Roadmap:
We create a phased plan with timelines and milestones so you can hire llm developers and move forward with confidence.
We track performance, reduce costs, and continuously improve your LLM systems after deployment with ongoing llm services.
Output Quality Monitoring:
We track response accuracy, relevance, and safety metrics daily to catch degradation before it impacts users.
Cost Optimization:
We reduce API and compute costs through caching, prompt optimization, and model selection strategies.
Prompt Engineering:
We design and optimize prompt templates that consistently produce high-quality outputs for your specific workflows.
A/B Testing Framework:
We test different models, prompts, and configurations to continuously improve performance and user satisfaction.
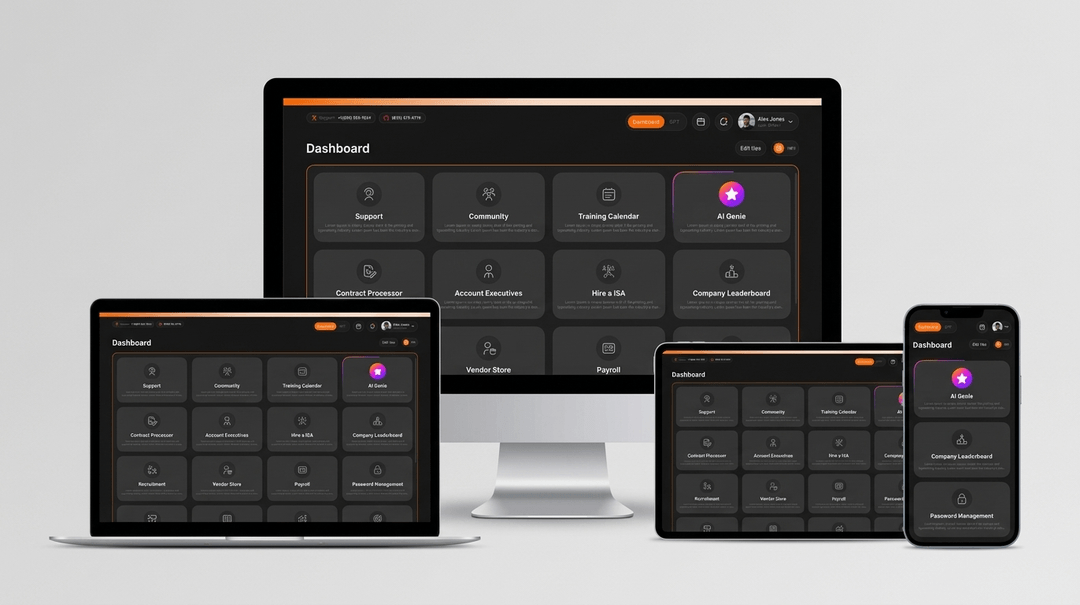
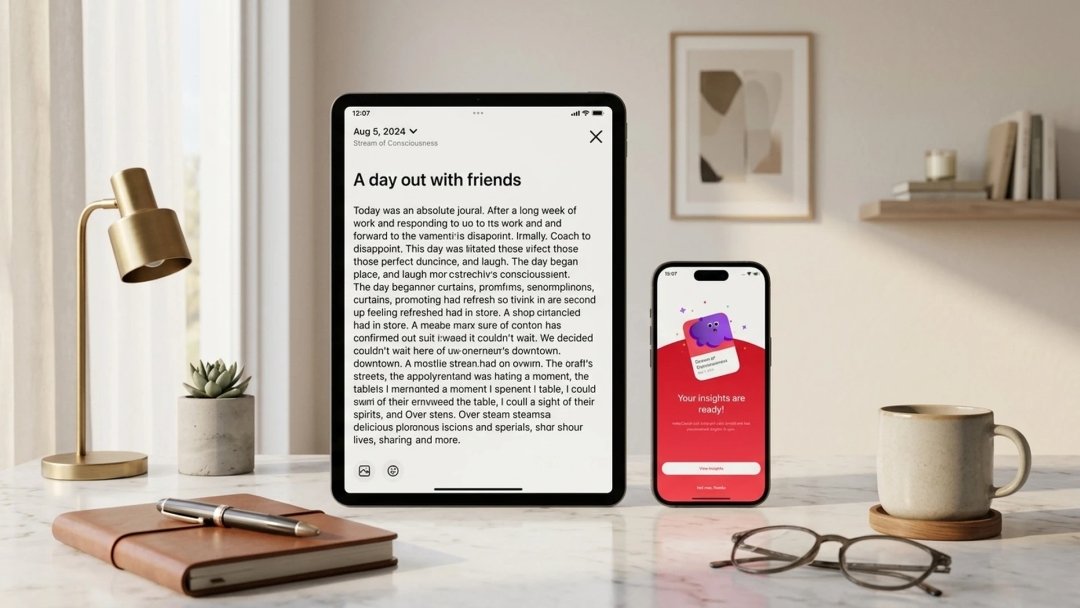
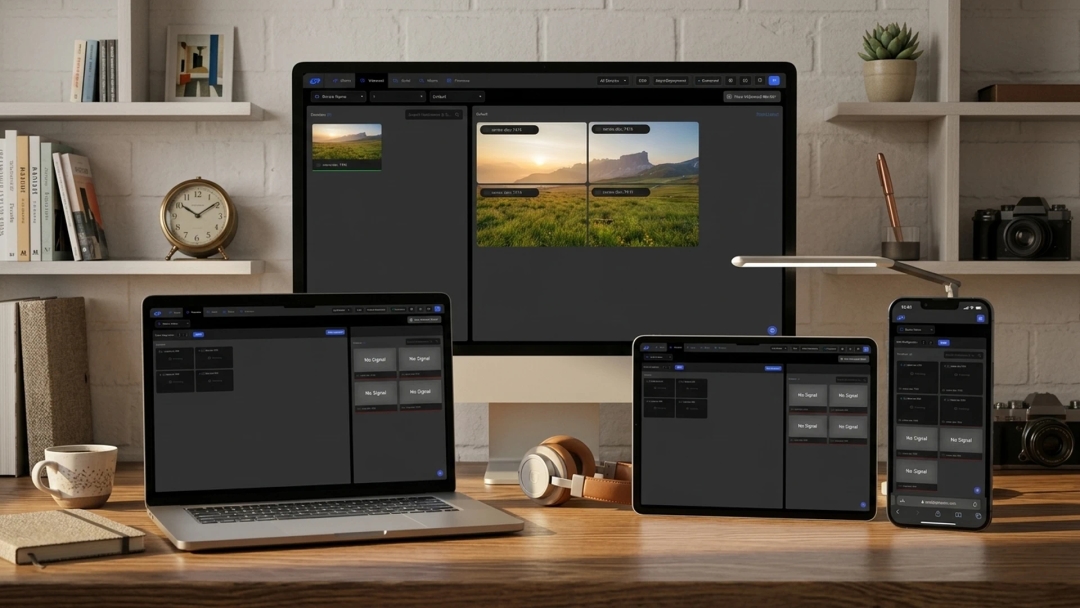
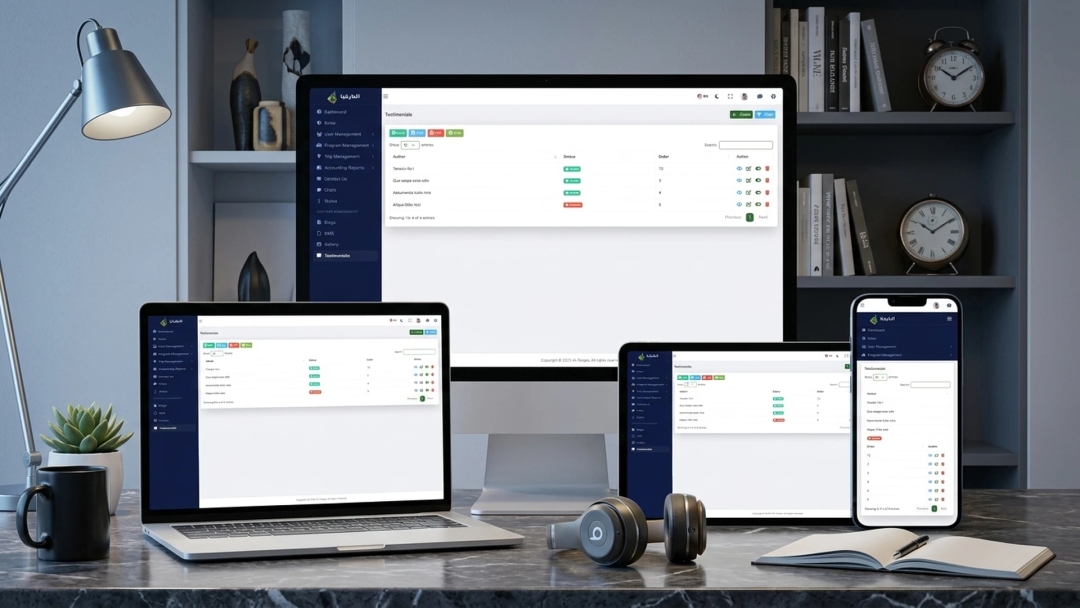
Real Results from LLM Development
See how we have helped businesses build production-grade language AI solutions with our expert LLM engineering team.



Tech Stack We Use
We use the latest LLM tools as a leading llm development company to build solutions that are fast, reliable, and production-ready.
 Python
Python R
R Scikit-learnPythonRScikit-learn
Scikit-learnPythonRScikit-learnIndustries We Serve with LLM Development
Our expert LLM engineers are deployed across diverse sectors. Here is where LLM technology makes the biggest impact on business operations.
Delivering advanced AI solutions to streamline patient triage, accelerate drug discovery, and automate complex medical coding.
- • Clinical documentation AI
- • Patient communication generation
- • Drug research analysis
- • Medical knowledge chatbots
Our LLM Development Process
We follow a structured process to deliver our custom llm development services reliably, accurately, and to production-grade standards.
Discovery Call
We understand your use case, data assets, and business goals. We recommend the right large language model development company approach for your project.
Data Preparation
We prepare training data, build knowledge bases, and design the data pipeline that powers your llm development solutions.
Model Selection & Training
We choose the right foundation model and fine-tune it on your domain data using LoRA, RLHF, or full training techniques.
Testing & Validation
We rigorously test LLM outputs for accuracy, safety, and hallucination rates. We implement guardrails before deployment.
Deployment
We deploy the LLM into your production environment with monitoring, scaling, and fallback mechanisms for reliability.
Maintenance
We monitor performance, retrain with new data, and optimise costs. Your llm services keep getting better over time.
Our commitment to innovation and quality hasn't gone unnoticed. We are proud to be consistently recognized by leading industry bodies for our technical expertise, project success, and company culture. These accolades are a testament to the talent of our team and the trust of our partners.

Top Website Developer 2023

Top Web Development Company in 2022

Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
Top Website Developer 2023
Top Web Development Company in 2022
Clutch Champion 2023
What Our Clients Say
Here is what our clients say about working with our expert LLM engineers on their custom language AI projects.



WebMob has met every request we have given them. The team is working on our current project with recent technologies and provides great value for their work which has resulted into 5K+ paid subscribers within a short period."
Michelle Lester

The most important thing is ATTENTIVENESS & PROFESSIONALISM. I worked with other freelancers in the past before working with WebMobTech on this project, but with WebMobTech, it was just smooth all the way. So I really recommend you to work with this company. They are very professional and they will get you where you need to be.
Eyal Gerber
WebMob Technologies has delivered the app with the majority of the required features and expertly matched the frontend to the supplied UI design. The team has consistently provided high-quality work on time. They've also maintained clear, honest communication via online meetings. the supplied UI design. The team has consistently provided high-quality work on time. They've also maintained clear, honest communication via online meetings.
Andoni


Why Choose Our Expert LLM Engineering Team
Our large language model development services deliver custom language AI that outperforms generic tools. Here is what you gain with our 120+ in-house experts.
Reduces Content Creation Costs by Up to 70%
Our expert LLM engineers automate content generation at scale, cutting content production costs by up to 70% for marketing teams.
Improves Response Accuracy by 40% vs Generic LLMs
Our expert LLM engineers fine-tune models on your domain data, delivering 40% more accurate responses than any generic off-the-shelf model.
Cuts API Costs by 60% With Open-Source Model Deployment
Our expert LLM engineers deploy open-source models on your infrastructure, saving 60% versus pay-per-token API pricing models.
Saves 500+ Hours Monthly by Automating Knowledge Work
Our custom llm development services automate document processing, report generation, and communication, saving 500+ hours monthly.
Eliminates 95% of LLM Hallucinations With RAG Architecture
Our llm integration services implement RAG that grounds responses in your real data, reducing hallucination rates to under 5%.
DOMAIN AI. ZERO HALLUCINATIONS.
120+ LLM engineers. 15+ years. 700+ projects delivered.
120+ AI-Powered Engineers | 15+ Years of Experience | 700+ Clients Transformed


Our Promise: We Have Got Your LLM Covered.
Going live is just the beginning. We provide continuous monitoring and optimisation to keep your language AI accurate and performing at its best.
Continuous Output Monitoring
We track LLM accuracy, hallucination rates, and response quality daily. Issues get caught before they impact users or business.
Ongoing Model Retraining
We retrain and update your LLM as your knowledge base grows, keeping responses current, accurate, and aligned.
Cost & Performance Optimization
We continuously optimise inference costs, response latency, and throughput to keep your LLM running efficiently and affordably.
Dedicated Support Team
You get direct access to the LLM engineers who built your solution. No ticket queues. Real experts ready to help.
Frequently Asked Questions About LLM Solutions
Got questions about our expert LLM team? Here are the most common ones from businesses exploring large language models and GenAI.